Random number generation using variadic template functions, and threading in C++11 and R with Rcpp
The Rcpp package allows R programmers to easily integrate C++ code and libraries with R. This allows C++ functionality to be called from R, which is useful for writing high performance R code or interfacing various libraries available in C++ with R. At Active Analytics we like this package a lot; it is very well maintained and its frequent improvement updates increases its ease of use. This makes life much easier. Thanks Rcpp guys. We have contributed our code on speed chain ladder analysis to the Rcpp gallery. Their suggestions on improvements made the code better and got us using the microbechmarks package. Check it out, it is useful.
This week’s action
C++11 is the ISO standard for C++ that was ratified in 2011, it includes many new features that extend C++ core language. We will be looking at three of these features namely:
- Variadic Templates
- Random Number Generation
- Multi-threading
Variadic templates allow the creation of templates that can take a variable number of template parameters. We will show how these can be used to create an interface (not in the formal OOP sense) to a family of template functions.
The C++11 extensible random number generation covers a convenient set of standard distribution and commonly used random number generation engines. In these examples we won’t worry about setting seeds - though doing this is straight forward. See the C++11 ISO standard for random number number generation n3551.
C++11 has extensive multi-threading capabilities, and we will be using some basic threading programming to speed up generation of larger vectors of random numbers.
We will use these three features to create functions that generate random numbers from distributions that are common in R’s stats package and we will compare the timings to the those for the native R stats sampling functions.
The core functionality comes from the template functions, which are called from R with wrapper functions. So the template function and some of the wrapper functions will be presented and then we will show bechmarks comparing the these with the native R functions.
The code in this blog entry is run/compiled on Ubuntu 14.04, core i7 processor having 16 GB RAM, using the g++ version 4.8.2 compiler, R version 3.1.0 and Rcpp version 0.11.2. The scripts are available on Github.
The C++ template functions
There are three important C++ function templates in this example, every other C++ function is (very easily) derived from them. The functions are as follows:
- A variadic template function for sampling random numbers from standard C++11 distributions that correspond with R standard distributions.
- A template function for filling part of a vector for the multi-threading case.
- A variadic template function for sampling random numbers from standard C++11 distribution multi-threading case.
From the above discription, you may be able to tell that the first and last templates are very similar. The second template simply acts as an enabler for the third. We will now look at the first case of the variadic function for sampling from the distributions.
C++ variadic template function sampling from standard distributions
Newcomers to variadic template functions may ask why it is useful in this case? Imagine you need to write functions to sample from a set of the C++11 standard distributions. Each distribution function has a different set of input arguments and each distribution is of a different type. You could go to the trouble of writing a separate function for each distribution, hmm … all that repeatative coding introducing those lovely bugs … yum. A variadic function is one that can take a variable number of arguments. In C++ (and R) this is signified with the ellipsis (…) and the fact that the function is also a template allows us to pass different types (in this case distributions) through the function. This allows us to create families of functions using very compact code in C++ with with little or no performance overhead.
In this example we have hard coded the random number generation engine as the mersenne twister mt19937_64 engine - which is the default for R but you could choose to represent it as a another template type parameter.
Below is the preample for the code, Rcpp flags and includes. The first two lines allow
sourceCpp() to be used without having to write out a whole bunch of flags to correctly compile the code.
// [[Rcpp::depends(Rcpp)]]
// [[Rcpp::plugins(cpp11)]]
#include <Rcpp.h>
#include <iostream>
#include <vector>
#include <iterator>
#include <algorithm>
#include <numeric>
#include <random>
#include <thread>
#include <sstream>
#include <utility>
using namespace std;
using namespace Rcpp;
This is the variadic template function for sampling from standard distributions:
/* Single Threaded Functions */
/*
* Generic Random Sampler Function
*
* D is the distribution type
* T is the return vector element type, e.g. int, double etc
* Args... args is for forwarding the list of arguments
*
*/
template <template<typename> class D, typename T, typename... Args>
SEXP randomCpp(int n, Args&&... args)
{
vector<T> rVec(n);
random_device rdev{};
mt19937_64 e{rdev()};
D<T> d{args... };
generate(rVec.begin(), rVec.end(), [&d, &e](){return d(e);});
return wrap(rVec);
}
This rather small piece of code is all we really need to sample from the C++11 standard distributions that correspond with the R standard distributions. Note: the line D<T> d{args... }; can be substituted for the D<T> d{forward<Args>(args)... };.
C++ variadic template function sampling from standard distributions: multi-thread version
Next we sample from the standard C++11 distributions using multi-threading. There are two functions, one an ordinary template function for filling a vector with random numbers from each thread and another a variadic template function similar to our first function for sampling distributions but with multi-threading functionality using std:::thread, std::thread::join etc …
In the template function below, each parallel thread process fills in a different set of indices of the vector. For instance thread 0 fills in position 0 then position 0 + nThread and so on so that adjacent positions in the vector are filled in by different threads.
// Template function for filling the vector
template<template<typename> class D, typename T>
void random_fill(D<T> d, vector<T> &rVec, int iThread, int nThread)
{
int startEl = iThread;
int i = iThread;
int vSize = rVec.size();
random_device rdev{};
mt19937_64 e{rdev()};
while(i < vSize)
{
rVec[i] = d(e);
i += nThread;
}
}
This is then the multi-thread version of the variadic template function for sampling from our distributions:
/* Generic sampling Template function as before but this is for multithreaded functions */
template <template<typename> class D, typename T, typename... Args>
SEXP randomCpp_par(int n, Args&&... args)
{
vector<T> rVec(n);
int nThreads = thread::hardware_concurrency();
D<T> d{args...};
vector<thread> threads;
for(int i = 0; i < nThreads; ++i)
{
threads.push_back(thread(random_fill<D, T>, d, ref(rVec), i, nThreads));
}
for_each(threads.begin(), threads.end(), mem_fn(&thread::join));
return wrap(rVec);
}
Just a quick health warning, in the above function we used the thread::hardware_concurrency() function to get the number of threads on the machine. There is no guarantee that this will work on every machine so if you are implementing this generally you may want to provide a way of specifying the number of threads.
Next we show how to make use of these functions in R.
Wrappers for the template functions
Now that we have template functions, we simply create the wrappers for R to call these template functions. We give two examples, the rest are given in the scripts located in our Github page.
/* Uniform distribution */
/* Single threaded case */
//[[Rcpp::export]]
SEXP runifCpp(int n, double min = 0, double max = 1)
{
return randomCpp<uniform_real_distribution, double>(n, min, max);
}
/* Multi-threaded case */
// [[Rcpp::export]]
SEXP runifCpp_par(int n, double min = 0, double max = 1)
{
return randomCpp_par<uniform_real_distribution, double>(n, min, max);
}
Simplicity itself.
Benchmarks in R
Here we show the code that compares the speed of calling R’s native random sampling function with calling C++11 functions from R using Rcpp.
Loading the required packages …
require(Rcpp)
require(microbenchmark)
sourceCpp("distributions.cpp")
Now for the benchmarks:
n = 1E3
# R benchmarks
rbaseOutput <- summary(microbenchmark(runif(n), rbinom(n, size = 10, prob = .5), rgeom(n, prob = .5),
rnbinom(n, size = 10, prob = .5), rpois(n, lambda = 1), rexp(n, rate = 1),
rgamma(n, shape = 1, rate = 1), rweibull(n, shape = 1, scale = 1), rnorm(n, mean = 0, sd = 1),
rlnorm(n, mean = 0, sdlog = 1), rchisq(n, df = 5), rcauchy(n), rf(n, df1 = 100, df2 = 100),
unit = "ms"))
# Rcpp benchmarks
benchmarks <- summary(microbenchmark(runifCpp(n), rbinomCpp(n, size = 10, prob = .5), rgeomCpp(n, prob = .5),
rnbinomCpp(n, size = 10, prob = .5), rpoisCpp(n, lambda = 1), rexpCpp(n, rate = 1),
rgammaCpp(n, shape = 1, rate = 1), rweibullCpp(n, shape = 1, scale = 1), rnormCpp(n, mean = 0, sd = 1),
rlnormCpp(n, mean = 0, sdlog = 1), rchisqCpp(n, df = 5), rcauchyCpp(n), rfCpp(n, df1 = 100, df2 = 100),
unit = "ms"))
# Re-basing Rcpp benchmarks over R
benchmarks[,2:6] <- benchmarks[,2:6]/rbaseOutput[,2:6]
benchmarks[,1] <- c("unif", "binom", "geom", "nbinom", "pois", "exp", "gamma", "weibull", "norm", "lnorm",
"chisq", "cauchy", "f")
names(benchmarks)[1] <- "distr"
benchmarks <- cbind("call" = "Rcpp", benchmarks)
Print of benchmarks relative to R. Numbers < 1 mean that the C++ function was faster than R’s native sampling function.
benchmarks
call distr min lq median uq max neval
1 Rcpp unif 0.4609558 0.4667480 0.4625994 0.4696180 0.4586505 100
2 Rcpp binom 3.9493424 3.9445322 3.9540118 3.9969629 8.1807132 100
3 Rcpp geom 0.6358461 0.6276375 0.6282880 0.6291987 0.6538925 100
4 Rcpp nbinom 1.6648628 1.6771171 1.6867045 1.6968584 4.4092474 100
5 Rcpp pois 0.8663546 0.8727853 0.8777564 0.8838252 1.0084569 100
6 Rcpp exp 1.2000240 1.1790077 1.1762633 1.1699420 1.3372701 100
7 Rcpp gamma 0.7128176 0.6943219 0.6998303 0.6960887 0.1828007 100
8 Rcpp weibull 0.7496463 0.7495913 0.7509407 0.7533291 0.7005617 100
9 Rcpp norm 0.6234178 0.6304958 0.6326794 0.6410322 0.5926444 100
10 Rcpp lnorm 0.6447391 0.6481345 0.6477939 0.6521936 0.7779146 100
11 Rcpp chisq 0.7847040 0.7518851 0.7295048 0.7117106 0.7100107 100
12 Rcpp cauchy 0.7784544 0.7970499 0.7977913 0.8052047 0.9729998 100
13 Rcpp f 0.9299477 0.9334680 0.9358100 0.9423901 1.1169572 100
There are a few anomalies which stand out if we do a plot of the median times …
require(ggplot2)
ggplot(benchmarks, aes(distr, median)) + geom_bar(stat = "identity") +
labs(x = "\nDistribution", y = "Time (Relative to R)\n",
title = "C++ time relative to R ( < 1 is faster than R)\n")
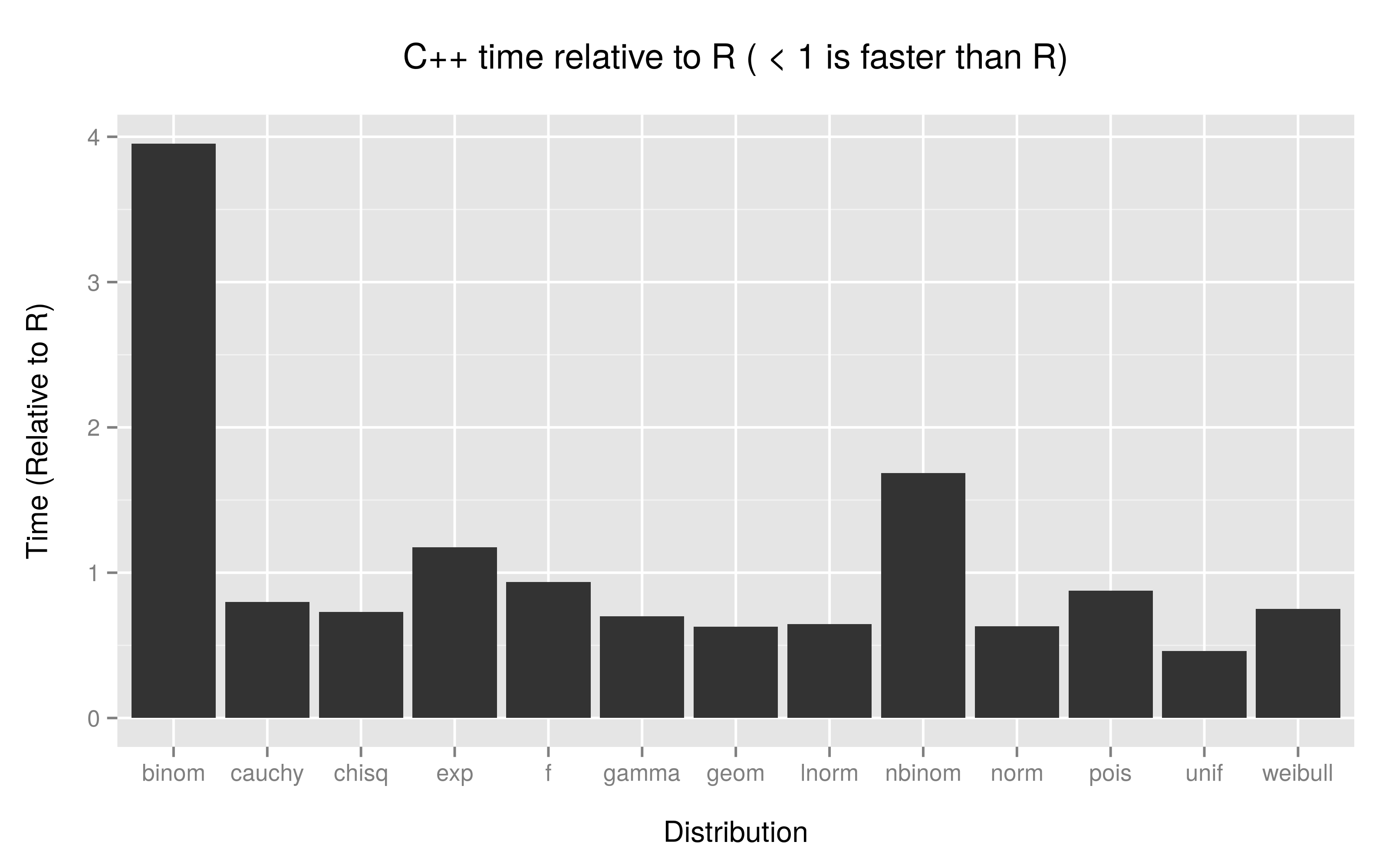
Bug? See what happens when we throw a nonsense probability at the C++ and native R functions for sampling from binomial distributions, certainly the R returning NA and a warning is preferential (at least to us) than the result from the C++ function. Remember however that C++ has no way of natively coding NA for integer types.
rbinomCpp(n = 10, size = 10, prob = 5)
[1] 10 10 10 10 10 10 10 10 10 10
rbinom(n = 10, size = 10, prob = 5)
[1] NA NA NA NA NA NA NA NA NA NA
Warning message:
In rbinom(n = 10, size = 10, prob = 5) : NAs produced
Multi-threading benchmarks
Lastly we throw in a couple of benchmarks for multi-threading. For smaller vector samples single threaded is faster, but for large number of random numbers, the multi-threaded approach is faster.
n = 1E3
> microbenchmark(runif(n), runifCpp(n, 0, 1), runifCpp_par(n, 0, 1))
Unit: microseconds
expr min lq median uq max neval
runif(n) 59.948 65.1865 68.4695 104.7715 175.263 100
runifCpp(n, 0, 1) 27.915 34.5890 37.9135 55.0760 82.104 100
runifCpp_par(n, 0, 1) 160.620 197.4535 209.6480 318.1040 728.858 100
n = 1E7 # below times = 1L cause life's too short
microbenchmark(runif(n), runifCpp(n, 0, 1), runifCpp_par(n, 0, 1), times = 1L)
Unit: milliseconds
expr min lq median uq max neval
runif(n) 389.77363 389.77363 389.77363 389.77363 389.77363 1
runifCpp(n, 0, 1) 148.71732 148.71732 148.71732 148.71732 148.71732 1
runifCpp_par(n, 0, 1) 76.62767 76.62767 76.62767 76.62767 76.62767 1
Conclusion
We expected much larger speed increases when switching to C++11 functions, but to our surprise some functions were slower than R’s native functions and the best was about twice as fast – perhaps we are routinely spoiled by larger speed-ups when abstracting to C++. There are clearly some implementation issues that need to be ironed out in the C++11 standard distributions but perhaps the important aspect of the upgrades to random number generation in C++11 is that we now have a framework that was previously absent, and we can now use this framework to create our own sampling distributions. As darts players say … “good marker”.
The other way of looking at these benchmarks is to praise R for having such a high performing set of distribution functions to sample from.